Как работает реляционная база данных
Часть 3
 Eleonora Pavlova
Eleonora Pavlova 
В прошлой серии мы подробно поговорили про статистику, оптимизатор запросов, алгоритмы объединения, теперь разберёмся с диспетчером данных.
Диспетчер данных
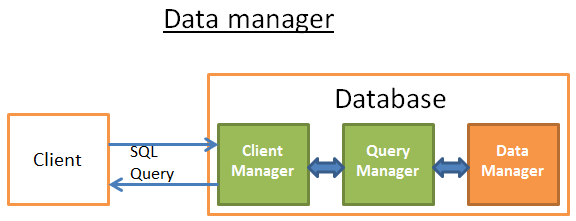
На этапе выполнения запроса диспетчеру запросов необходимы данные таблиц и индексов, за ними он обращается к диспетчеру данных. Здесь есть два сложных момента:
- Реляционные базы данных работают по транзакционной модели. Другими словами, вы не можете получать любые данные в любой отрезок времени, если в этот момент данные используются / изменяется кем-то ещё;
- Извлечение данных - самая медленная операция, поэтому диспетчер данных должен уметь сохранять полученные данные в буфер памяти.
Давайте посмотрим, как базы данных решают эти проблемы.
Диспетчер кэша
Для повышения производительности во всех современных БД есть диспетчер кэша.
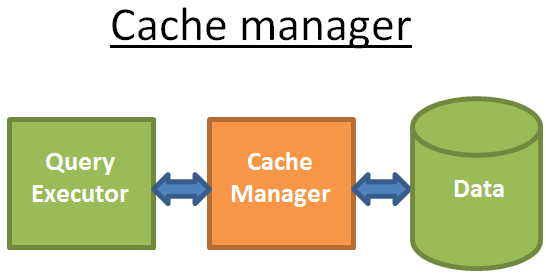
Таким образом, диспетчер запросов получает данные не напрямую из файловой системы, а из буферного пула диспетчера кэша. Это очень сильно ускоряет работу БД. Трудно рассчитать математически, насколько именно такой подход ускоряет извлечение данных - и во многом это зависит от типа накопителя в базе данных (HDD, SSD, дисковые массивы RAID), а также от видов операций: последовательный доступ (например, полное сканирование) или произвольный (например, по ID строки), чтение или запись… Но можно сказать, что получение данных из памяти в 100-100 000 раз быстрее, чем с диска. Однако, и здесь свой нюанс: данные должны оказаться в буферном пулле диспетчера кэша до того, как их запросят, иначе диспетчер запросов обратится к диску.
Предвыборка данных
Для этого существует предвыборка данных. Диспетчер запросов знает (благодаря статистике), какие данные есть на диске, и какие данные ему понадобятся (поскольку ему известен план выполнения запроса). Работает это примерно так: во время обработки первого набора данных, диспетчер запросов просит диспетчер кэша предварительно загрузить второй набор данных в буфер; во время обработки второго набора данных, диспетчер кэша получает команду предварительно загрузить третий набор данных и удалить из кэша первый. И так далее. Вместе с данными диспетчер кеша сохраняет в буферный пул дополнительную информацию (фиксатор – latch), чтобы своевременно очищать кэш, если данные более не нужны.
В некоторых БД диспетчер запросов не имеет возможности знать заранее, какие данные ему понадобятся — в этом случае осуществляется предвыборка предполагаемых необходимых данных (например, если диспетчеру запросов понадобились данные 1, 3, 5, скорее всего, он в скором времени запросит и данные 7, 9, 11). Иногда также используется последовательная предвыборка (когда диспетчер кеша просто подгружает в буфер данные, следующие сразу за запрошенными).
Для измерения эффективности предвыборки данных в современных БД есть коэффициент попадания в кэш. Он отражает, насколько часто запрашиваемые данные были получены из буферного пула, без обращения к диску. К слову, низкий коэффициент ещё не означает, что предвыборка данных работает плохо — подробнее об этом можно прочитать в документации Oracle.
Разумеется, объём буферной памяти не безграничен, и чтобы загружать новые данные, нужно очищать кэш от старых, это достаточно ресурсозатратная операция. Если у вас есть часто выполняемый запрос, не имеет смысла каждый раз загружать его в кеш, а потом удалять.Для таких случаев современные БД используют стратегию замены буфера.
Стратегии замены буфера
Большинство баз данных (например, SQL Server, MySQL, Oracle, DB2) используют алгоритм вытеснения по давности использования - LRU (Least Recently Used). Идея в том, чтобы хранить в кеше только данные, которые только что использовались, и значит, скорее всего, в ближайшее время снова будут использоваться.
Схематично это можно представить следующим образом:
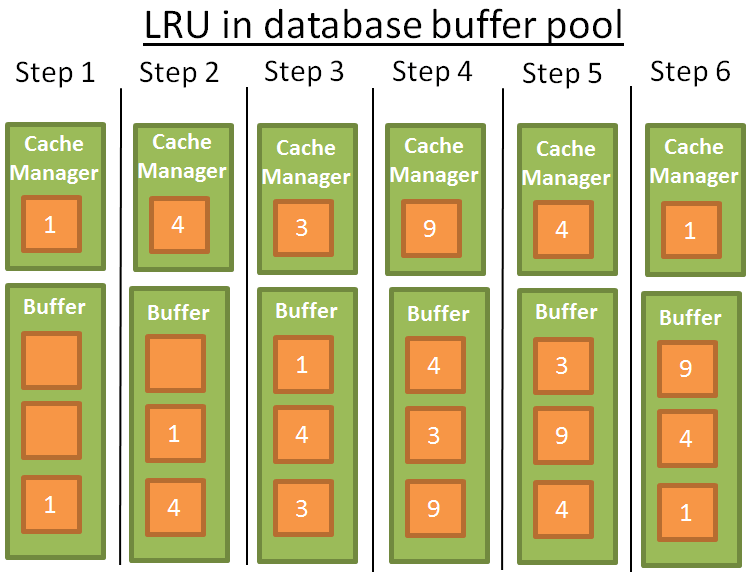
Для простоты будем считать, что данные в буфере не фиксированы (то есть их можно удалить). В нашем примере буфер может хранить 3 набора данных. Алгоритм действует следующим образом:
- диспетчер кэша использует набор 1 и помещает его в пустой буфер;
- далее он использует набор 4 и помещает его в буфер;
- затем используется набор 3, который также отправляется в буфер;
- диспетчер кеша использует набор 9 — буфер переполнен, поэтому удаляется набор 1, который использовался наиболее давно, набор 9 помещается в буфер;
- диспетчер кэша использует набор 4 — он уже есть в буфере и становится только что использованным набором данных;
- диспетчер запроса использует набор 1 — буфер переполнен, поэтому набор 9 удаляется как наиболее давно использованный, набор 1 помещается в буфер.
И так далее.
Этот алгоритм работает хорошо, но у него есть некоторые ограничения. Например, в случае полного сканирования большой таблицы. Если размер таблицы / индекса больше размера буфера, данный алгоритм удалит все предыдущие значения в кеше, хотя данные полного сканирования скорее всего будут использованы лишь один раз.
Чтобы такого не случалось, некоторые БД добавили специальные правила. Пример из документации Oracle: «В случае очень больших таблиц база данных, как правило, считывает наборы данных напрямую, без загрузки в кеш. Если таблица средних размеров, может использоваться как прямое считывание, так и загрузка из кеша. Если БД решает использовать чтение из кеша, данные помещаются в конец списка LRU, чтобы избежать очистки кеша».
Существует улучшенная версия алгоритма — LRU-K, используемая, например, в SQL Server (K=2). В случае LRU (где K=1) учитывается только, когда данные использовались в последний раз. Улучшенная версия анализирует, какие данные использовались последние K раз. Часто используемые данные обладают большим весом. При загрузке в кеш нового набора данных, старые часто используемые данные не удаляются (поскольку количество раз их использования больше). Но в случае, если данные не используются часто, алгоритм не хранит их в кеше. Таким образом, со временем вес данных снижается, если они реже используются.
Расчет веса данных требует некоторых системных ресурсов, поэтому SQL Server использует только K = 2 — наиболее оптимальный вариант с точки зрения ресурсозатрат.
Более подробную информацию про LRU-K алгоритм вы найдёте в этой работе.
Другие алгоритмы
Есть и другие алгоритмы замены буфера: 2Q и CLOCK (похожи на LRU-K); MRU (Most Recently Used) — использует ту же логику, что и LRU, но другие правила; LRFU (Least Recently and Frequently Used), и так далее. В некоторых базах данных можно самостоятельно выбирать алгоритм.
Буфер записи
Мы говорили только про буферы чтения, которые подгружают данные перед их использованием. Но в базе данных есть и буферы записи, которые позволяют группировать данные и передавать их наборами, что сокращает количество обращений к диску.
Следует помнить, что в буфере хранятся страницы (минимальная единица данных), а не ряды (то, как мы визуально представляем данные). Если страница в буферном пуле была изменена, но не записана на диск, она считается «грязной». Существуют различные алгоритмы для вычисления лучшего времени для записи «грязных» страниц на диск, все они вписываются в транзакционную модель, о которой и поговорим далее.
Диспетчер транзакций
Основное правило транзакционной модели: одна транзакция — один запрос.
Давайте сначала разберёмся, что же такое ACID-транзакции.
ACID-транзакция предусматривает четыре условия:
- Неразрывность: транзакция либо выполнена полностью, либо не выполнена вовсе, даже если она длится 10 часов. Если происходит сбой, всё возвращается в состояние до начала транзакции;
- Изолированность: если одновременно выполняются транзакции A и B, ни одна из них никак не может повлиять на результат второй;
- Надёжность: как только транзакция успешно завершилась, результат сохраняется в БД, независимо от любых обстоятельств (падение или ошибки).
- Однородность: только корректные (с точки зрения реляционных и функциональных ограничений) данные записываются в БД, что обеспечивается неразрывностью и изолированностью транзакций.

Во время транзакции может выполняться несколько SQL запросов на чтение, создание, обновление и удаление данных. Трудности начинаются, когда две транзакции используют одни и те же данные. Классический пример - перевод денег со счета А на счет Б. Представим, что у нас есть 2 транзакции:
- Транзакция 1 снимает 100$ со счета А и переводит на счёт B;
- Транзакция 2 снимает 50$ со счета А и переводит на счёт B.
Вернёмся к характеристикам ACID-транзакций:
- Неразрывность гарантирует, что независимо от того, что произойдёт во время транзакции 1 (сбой сервера, сбой в сети), никогда не получится, что 100$ будут сняты со счёта А, но не дойдут до счёта B.
- Изолированность гарантирует, что если обе транзакции выполнятся одновременно, в результате, со счёта А спишутся 150$ и на счёт В будут переведены 150$; ситуация, при которой, например, со счёта А списано 150$, а на счёт В пришло только 50$ (потому что транзакция 2 частично затёрла действия транзакции 1), невозможна.
- Надёжность гарантирует, что даже если после выполнения транзакции 1 база упадёт, результат транзакции сохранится в БД.
- Однородность гарантирует, что денежные суммы не будут изменяться в системе.
Многие современные базы данных не используют изолированность по умолчанию, поскольку она очень ресурсозатратна. В SQL 4 уровня изолированности:
- Сериализованные транзакции (включены по умолчанию в SQL): максимально изолированные. Две одновременно происходящие транзакции на 100% изолированы друг от друга.
- Повторяющееся («фантомное») чтение (включено по умолчанию в MySQL): транзакции изолированы во всех случаях, кроме одного - если транзакция успешно завершается и добавляет новые данные, эти данные будут доступны в других, всё ещё совершаемых, транзакциях. Но если транзакция изменяет уже существующие данные, по её завершению эти изменения не будут доступны параллельно выполняемым транзакциям. Таким образом, нарушение изолированности происходит лишь в случае добавления новых данных.
Например, транзакция A совершаетSELECT COUNT (1) from TABLE_X
после чего транзакция B добавляет новые данные в TABLE_X; если транзакция A снова выполнит count(1), результат будет уже другим.
- Чтение фиксированных данных (включено по умолчанию в Oracle, PostgreSQL и SQL Server): повторяющееся чтение с дополнительным нарушением изоляции. Транзакция А читает данные D, а затем эти данные изменяются (или удаляются) транзакцией B, если транзакция A снова считает данные D, изменения, внесённые B, будут ей доступны. Это не повторяющееся чтение.
- Чтение нефиксированных данных - самый низкий уровень изолированности. Это чтение фиксированных данных с дополнительным нарушением изолированности. Транзакция A читает данные D, затем эти данные D изменяются транзакцией B (транзакция ещё не завершена), если в этот момент транзакция А параллельно считает данные D, внесённые изменения будут ей доступны. Если по каким-то причинам транзакция B откатывается назад, то данные D, считанные транзакцией A во второй раз, не будут иметь смысла, так как эти изменения были внесены отменённой транзакцией B. Такое чтение называется «грязным».
Многие базы данных добавляют свои собственные уровни изоляции (например, снэпшоты, используемые в PostgreSQL, Oracle и SQL Server). И, разумеется, в большинстве БД реализованы не все уровни изоляции (чтение нефиксированных данных встречается не часто).
Уровень изоляции, установленный по умолчанию, можно изменить при первом соединении (буквально одной строчкой кода).
Управление многозадачностью
Наибольшая трудность в обеспечении изолированности, неразрывности и однородности связана с операциями добавления, изменения и удаления одних и тех же данных.
Если все транзакции только считывают данные, они могут происходить параллельно, не влияя друг на друга. Если хотя бы одна из транзакций изменяет данные, считываемые другой транзакцией, базе данных необходимо скрыть это изменение от других транзакций, а также гарантировать, что внесённое изменение не будет перезаписано другой транзакцией, которой эти изменения не были видны.
Для этого и необходимо управление многозадачностью.
Самый простой способ решения вышеописанной проблемы - выполнение каждой транзакции по отдельности (т.е. последовательно). Абсолютно не масштабируемый вариант: если использовать лишь одно ядро многоядерного процессора — об эффективности не может быть и речи.
Для решения этой проблемы при каждом запуске или отмене транзакции нужно:
- анализировать все операции всех транзакций;
- проверять транзакции на предмет конфликтов (например, если две или более транзакций изменяют/считывают одни и те же данные);
- изменять порядок совершения операций внутри конфликтующих транзакций;
- выполнять конфликтующие части транзакций отдельно, в определенном порядке (в то время как не конфликтующие транзакции продолжают выполняться параллельно);
- наконец, учитывать, что транзакция может быть отменена.
Другими словами, это проблема нахождения оптимальных графиков выполнения транзакций. Базы данных не могут тратить слишком много времени на нахождение самого оптимального графика для каждой новой транзакции, поэтому они выбирают менее эффективные подходы и тратят время на разрешение конфликтующих транзакций.
Диспетчер блокировок
Чтобы справиться с проблемами многозадачности, многие БД используют блокировки и/или управление версиями данных. Рассмотрим виды блокировок.
Полная блокировка
В целом, идея блокировки такова: если транзакции необходимы какие-либо данные, она их блокирует; если другой транзакции понадобятся эти же данные, ей придётся ждать, пока первая транзакция разблокирует доступ к ним.
Однако, крайне неразумно использовать полную блокировку для транзакции, которой необходимо только считать данные, поскольку другим транзакциям, которым также необходимо только считать данные, придётся ждать.
В таких случаях лучше использовать блокировку с обеспечением совместного доступа, которая работает так:
- если транзакции нужно лишь прочитать данные А, она блокирует данные с обеспечением совместного доступа и считывает их;
- если другой транзакции также нужно лишь прочитать данные А, она точно также их блокирует и считывает;
- если какой-то транзакции нужно внести изменения в данные А, она полностью блокирует их, однако ей приходится ждать, пока предыдущие две транзакции снимут совместную блокировку с данных.
При этом, если данные заблокированы полностью, транзакции, которая только считает данные, всё равно придётся ждать окончания полной блокировки для последующей блокировки с обеспечением совместного доступа.
Вернёмся к диспетчеру блокировок.
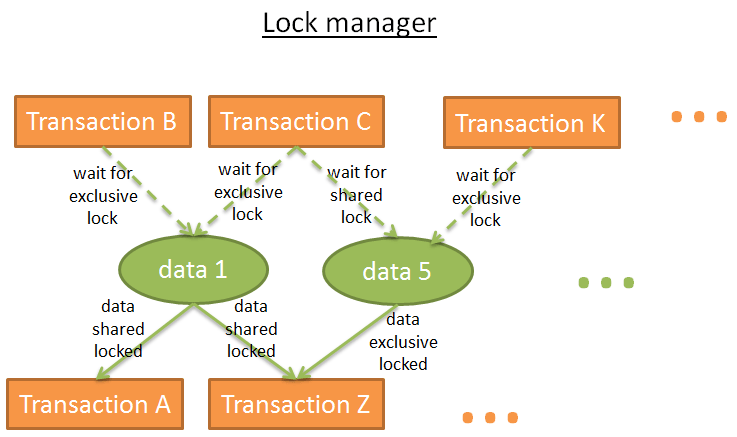
Диспетчер блокировок
Диспетчер блокировок- это процесс, накладывающий и снимающий блокировки. Данные о блокировках хранятся в хеш-таблице (где ключ — заблокированные данные). Диспетчер знает, какие именно транзакции блокируют данные и какие транзакции ожидают разблокировки данных.
Взаимная блокировка
Однако, случаются ситуации, когда транзакциям придётся ждать разблокировки данных бесконечно:
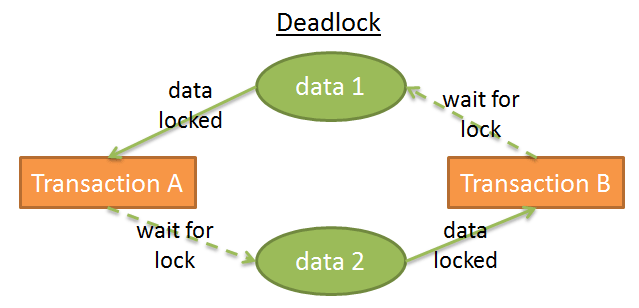
На данной схеме транзакция A полностью блокировала данные 1 и ожидает разблокировки данных 2. При этом, транзакция B полностью блокировала данные 2 и ожидает разблокировки данных 1.
В такой ситуации диспетчер блокировок решает, какую блокировку отменить для разрешения конфликта. И это непростое решение. Стоит ли отменить транзакцию, изменившую наименьшее количество данных? Или же отменить самую последнюю транзакцию, поскольку клиенты других транзакций ожидали дольше? Стоит ли отменить наиболее короткую транзакцию? В случае отмены, на какое количество других транзакций это повлияет?
Но до принятие решения диспетчер блокировок должен убедиться, что взаимная блокировка действительно произошла. Если это так, это отразится в хеш-таблице блокировок в виде цикличного процесса. Однако, проверять всю таблицу на наличие таких циклов слишком ресурсозатратно. Поэтому часто просто используют таймауты: если разблокировка не происходит в течение заданного таймаута, значит, произошла взаимная блокировка.
Прежде, чем блокировать данные, диспетчер блокировок может проверить, не приведёт ли это к взаимоблокировке. Но, увы, такое вычисление тоже очень ресурсозатратно, поэтому часто используют набор простых правил.
Двухфазная блокировка
Наиболее просто обеспечить полную изолированность блокировок, если применять блокировку в начале транзакции и снимать по факту её завершения. Таким образом, транзакции приходится ждать снятия всех предыдущих блокировок до начала выполнения и снимать собственную блокировку после окончания выполнения. Звучит отлично, но между всеми этими ожиданиями потеряется куча времени.
Более мудрый подход, реализованный в DB2 и SQL Server, - протокол двухфазной блокировки. В этом случае транзакция делится на две части:
- Фаза подъёма: транзакция может накладывать блокировку, но не может снимать её;
- Фаза спада: транзакция может снять блокировку (с данных, которые она уже обработала и к которым не будет возвращаться), но не может накладывать новые блокировки.
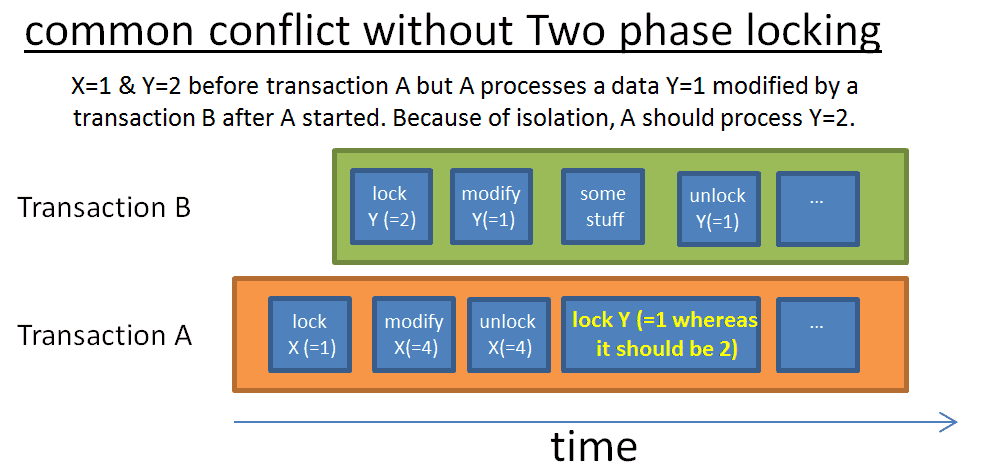
Таким образом, блокировки, которые уже не нужны, снимаются, сокращая время ожидания других транзакций. Также благодаря протоколу исключаются ситуации, когда транзакция получает данные, в которые были внесены изменения до начала транзакции (соответственно, они не соответствуют запрашиваемым данным).
Протокол двухфазной блокировки работает отлично, кроме случаев, когда транзакция, изменившая данные и снявшая блокировку, отменяется. Может получиться, что другая транзакция в этот момент считывает изменённые данные, а изменения отменяются. Во избежание подобных ситуаций все полные блокировки должны сниматься только по окончании транзакции.
Конечно, в реальных базах данных используются и более глубокие блокировки (блокировки рядов, страниц, разделов, таблиц, табличных пространств).
Также для решения проблем многозадачности БД использую управление версиями данных, суть которого в следующем:
- транзакции могут изменять одни и те же данные одновременно;
- у каждой транзакции своя копия (версия) данных;
- если две транзакции изменяют одни и те же данные, только одно изменение в итоге вступает в силу — вторая транзакция отменяется (и затем, возможно, выполняется заново).
Управление версиями данных улучшает производительность БД, поскольку читающие транзакции не блокируют записывающие транзакции, и наоборот. Плюс мы экономим ресурсы, которые бы использовал медленный диспетчер блокировок.
Блокировка и управление версиями данных — это два разных подхода (пессимистичный и оптимистичный). У обоих свои плюсы и минусы (в зависимости от количества чтений/записей).
Рекомендую к прочтению презентацию от PostgreSQL про мультиверсионное управление многозадачностью.
Некоторые БД (DB2 до версии 9.7, SQL Server за исключением снепшотов) используют только блокировки. Другие (PostgreSQL, MySQL, Oracle) используют как блокировки, так и управление версиями данных. А вот базы данных, использующие только управление версиями данных, мне не известны.
Стоит отметить, что управление версиями данных иногда может внести хаос в индексы: в уникальных индексах могут появиться дубликаты, записей в индексах может оказаться больше, чем в таблице и т.д.
Правка (08/20/2015 ) в комментариях поделились информацией, что Firebird и Interbase применяют исключительно управление версиями данных.
В части про уровни изолированности мы выяснили, с повышением уровня увеличивается и количество блокировок, а значит и время ожидания транзакций снятия этих блокировок. Именно поэтому большинство БД не используют по умолчанию сериализованные транзакции (наивысший уровень изолированности).
Как обычно, советую изучить тему подробнее в официальных доках MySQL, PostgreSQL или Oracle.
Диспетчер логов
Итак, мы знаем, что для увеличения производительности, БД загружает данные в буферный пул. Но если сервер падает во время транзакции, данные, которые находились в памяти во время падения, будут утеряны, а это нарушает принцип надёжности транзакций.
Можно всё записывать сразу на диск, но если в процессе сервер выйдет из строя, у вас на диске в итоге будет лишь часть обновлённых данных, а это в корне нарушает принцип неразрывности транзакций.
В подобных случаях любые изменения, внесённые прерванной транзакцией, должны быть отменены.
Сделать это можно двумя способами:
- Теневые копии: каждая транзакция создаёт свою копию БД (или её части) и работает с этой копией. В случае ошибок копия удаляется. В случае успешного завершения транзакции, БД принимает данные из теневой копии, а старые удаляет.
- Лог транзакций: перед каждой записью на диск, БД пишет детали транзакции в лог, чтобы в случае падения / отмены транзакции, она знала, как удалить/завершить незаконченную транзакцию.
Протокол предварительного логирования
Использование теневых копий в больших базах данных с миллионами транзакций — это смерть для дисковой системы. Поэтому большинство БД используют лог, который должен храниться на стабильном накопителе (не будем вдаваться в детали, но как минимум необходимо использовать дисковые массивы RAID).
Большинство БД (Oracle, SQL Server, DB2, PostgreSQL, MySQL, SQLite) используют протокол предварительного логирования (WAL – Write-Ahead Logging), работа которого основана на трёх правилах:
- Каждое внесённое в БД изменение записывается в лог транзакций, и данная запись должна происходить до того, ка кданные запишутся на диск;
- Записи в лог транзакций делаются в логической последовательности выполнения транзакций:
- Когда транзакция фиксируется, запись об этом должна появиться в логе до того, как транзакция успешно завершится.
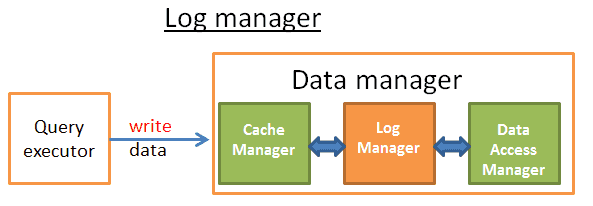
По идее, диспетчер логов должен располагаться между диспетчером кеша и диспетчером доступа к данным (который записывает данные на диск) и записывать каждую операцию изменения/удаления/создания/отката в лог транзакций до того, как эти изменения попадут на диск. Верно?
А вот и нет. После всего, что мы с вами узнали, несложно догадаться, что и тут, как всегда в случаях с базами данных, ключевая и решающая деталь — общая производительность. Если диспетчер логов будет тормозить, это негативно скажется на работе всей БД.
ARIES
В 1992 году инженеры IBM «создали» расширенную версию WAL под названием ARIES, которая в той или иной степени реализована во всех современных БД. Я написал «создали» в кавычках, потому что согласно этому курсу MIT, инженеры IBM сделали ничто иное как собрали воедино все лучшие практики восстановления транзакций. Но в данном случае это мелочи. Я прочёл большую часть научно-исследовательской работы по ARIES – на самом деле увлекательно! Далее я сделаю краткий обзор технологии, а за подробностями прошу обращаться к первоисточнику.
Итак, основные задачи, решаемые ARIES (Algorithms for Recovery and Isolation Exploiting Semantics):
а) обеспечить высокую производительность при записи в лог транзакций,
б) обеспечить быстрое и надёжное восстановление.
По каким причинам транзакция может быть отменена?
- Её отменил пользователь;
- Сбой сервера, сбой в сети;
- В связи с тем, что транзакция нарушила целостность базы данных (например, у вас на столбце ограничение UNIQUE, а транзакция добавила дубликат);
- Из-за взаимной блокировки.
В некоторых случаях (например, сбой в сети) БД может восстановить транзакцию. Чтобы понять, как это происходит, разберёмся, какая информация хранится в логе.
Логи
В результате любой операции в логе создаётся запись, которая состоит из следующих компонентов:
- LSN (Log Sequence Number): уникальный регистрационный номер транзакции, присваиваемый в хронологическом порядке (на самом деле, всё немного сложнее, но опустим детали). Это означает, что если операция A произошла раньше операции B, регистрационный номер A будет меньше, чем у B;
- TransID: идентификатор транзакции, совершившей операцию;
- PageID: место на диске, где хранятся изменённые данные. Минимальная единица данных — страница, поэтому место хранения изменённых данных это место хранения страницы;
- PrevLSN: ссылка на предыдущую запись в логе об этой транзакции;
- UNDO: описание способа отменить результат транзакции; например, если это операция обновления, в UNDO сохранится либо значение/состояние данных до внесения изменений (физическое UNDO), либо информация об обратной операции, которая вернёт прежние данные (логическое UNDO); ARIES использует только логическое UNDO;
- REDO: описание способа повторного выполнения операции; то есть сохранится либо значение/состояние данных после внесения изменений, либо сама операция;
- в логе ARIES также имеются поля UndoNxtLSN и Type.
Насколько мне известно, PostgreSQL – единственная БД, не использующая UNDO, это связано с управлением версиями данных. Вместо этого там реализован сборщик мусора, удаляющий старые версии данных.
Небольшой наглядный пример лога запроса UPDATE FROM PERSON SET AGE = 18; Предположим, данный запрос выполняется в транзакции 18.
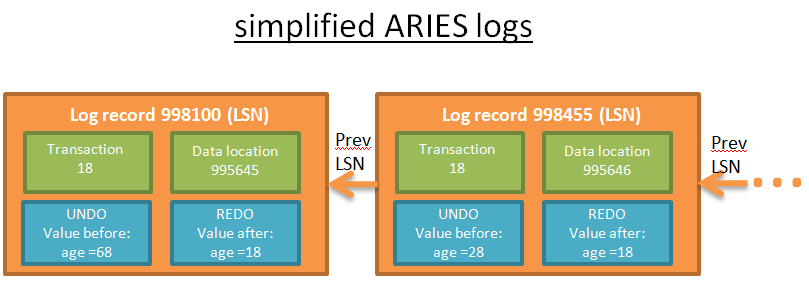
У каждого лога уникальный регистрационный номер . Связанные логи относятся к одной и той же транзакции.
Буфер логов
Для оптимизации работы логов существует буфер логов.
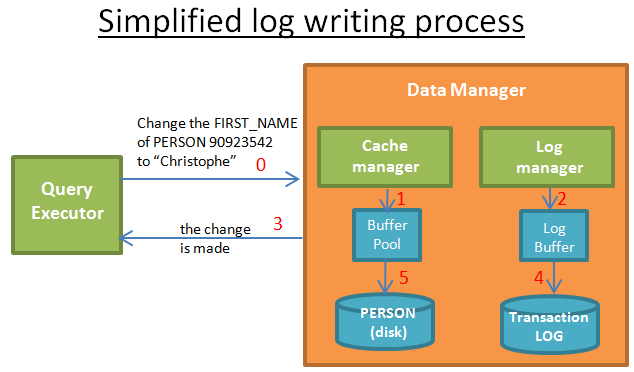
Упрощённо процесс записи в лог происходит следующим образом:
- исполнитель запросов запрашивает внесённые изменения;
- диспетчер кеша сохраняет изменения в буфере;
- диспетчер логов помещает соответствующую запись в в буфер;
- на этом этапе исполнитель запросов считает, что операция выполнена (и можно запрашивать другие данные);
- затем диспетчер логов вносит соответствующую запись в лог транзакций (решение о том, когда именно вносить эту запись, принимает алгоритм);
- наконец, диспетчер кеша записывает изменение на диск (решение о том, когда вносить эту запись, также основано на алгоритме).
Если транзакция фиксируется, это значит, что все вышеперечисленные пункты выполнены для всех операций внутри транзакции. В конечном счёте, запись в лог транзакций — достаточно быстрая операция, поскольку это всего лишь запись лога в произвольное место в логе транзакций. В сравнении с этим запись на диск — более сложная и долгая операция, подразумевающая запись данных на диск таким образом, чтобы в дальнейшем их было легко считать.
Стратегии восстановления
В целях повышения производительности последний (6ой) пункт в некоторых БД может выполняться после фиксации транзакции, поскольку в случае падений системы транзакцию всё же можно восстановить с помощью информации REDO в логе. Такая стратегия называется произвольной (NO FORCE POLICY).
Однако, для снижения нагрузки во время восстановления БД может применить и силовую стратегию (FORCE POLICY) — когда запись изменений на диск диспетчером кеша производится только и исключительно до фиксации транзакции.
Второе принципиальное различие в стратегиях - применение поэтапной (STEAL – step-by-step policy) записи данных на диск, или же одномоментной записи, когда буфер дожидается фиксации коммита, и потом всё разом пишет на диск (NO-STEAL policy). В данном случае выбор стратегии зависит от того, что вам нужно: быстрая запись, но длительное восстановление с помощью UNDO в логе, или быстрое восстановление.
Кратко различия в стратегиях:
- для стратегии STEAL / NO FORCE необходимы UNDO и REDO; наиболее производительный подход, но с более сложной структурой логов и восстановительных процессов (как в ARIES); применяется в большинстве БД — эту информацию я много где встречал, хотя ни разу не видел явно задокументриванной;
- для стратегии STEAL / FORCE нужен только UNDO;
- для стратегии NO STEAL / NO FORCE нужен только REDO;
- стратегия NO STEAL / FORCE не использует никаких записей в логах, но наименее продуктивна и требует огромного количество памяти.
Процесс восстановления
Итак, у нас есть все засипи в логах, давайте посмотрим, как их используют.
Предположим, стажёр уронил нашу базу данных (правило №1: в любой непонятной ситуации виноват стажёр!). Перезапускаем БД, начинается процесс восстановления.
В ARIES этот процесс выглядит так:
- Анализ: процесс восстановления считывает весь лог транзакций , чтобы восстановить последовательность операций во время сбоя. Вычисляется, какие операции необходимо откатить (все не зафиксированные транзакции), и какие данные необходимо было записать на диск во время падения;
- Повторное выполнение: начиная с конкретной записи в логе (определённой во время анализа), выполняется REDO для приведения БД в состояние до падения. REDO записи в логе обрабатываются в хронологическом порядке благодаря уникальным регистрационным номерам транзакций (LSN). Процесс восстановления считывает номер LSN страницы на диске
Если LSN(страницы на диске) > = LSN(записи в логе), это значит, что изменения в данные уже были внесены до сбоя (значение было переписано операцией, произошедшей после записи в логе и перед падением). Соответственно, никаких изменений не вносится. Если же LSN(страницы на диске) < LSN(записи в логе), страница на диске обновляется.
Для упрощения процесса восстановления REDO иногда выполняется даже для транзакций, которые будет отменены (хотя, думаю, в современных БД так уже не делают); - Отмена: наконец, откатываются все транзакции, незавершённые на момент падения БД. Откат начинается с последних записей в логе каждой такой транзакции, то есть UNDO записи обрабатываются в обратном порядке (используя PrevLSN в логе).
Во время восстановления действия лога транзакций и процесса восстановления должны синхронизироваться, чтобы данные, записываемые на диск, соответствовали записям, заносимым в лог. В данном случае можно было бы сразу удалять из лога записи о транзакциях, которые отменяются, но технически это не так просто сделать. Вместо этого, ARIES вносит в лог записи, которые логически удаляют записи об отменённых транзакциях.
Когда транзакция отменяется «вручную» или диспетчером блокировок (для снятия взаимной блокировки) или из-за сбоев в сети, этап анализа не обязателен, поскольку информация о том, что нужно повторно выполнить или отменить, есть в двух хранящихся в памяти таблицах — таблице транзакций (хранит информацию о состоянии всех текущих транзакций) и таблице грязных страниц (хранит информацию о данных, которые необходимо записать на диск). Данные в этих таблицах обновляются диспетчерами кеша и транзакций при каждой новой транзакции. При падении системы эти таблицы стираются из памяти.
Задача этапа анализа как раз в том, чтобы восстановить эти таблицы после падения, используя записи в логе транзакций. Для ускорения процесса анализа в ARIES есть контрольные точки: время от времени данные из таблицы транзакций и таблицы грязных страниц записываются на диск вместе с последним на момент записи номером (LSN). Таким образом, во время анализа обрабатываются только логи, идущие после этого LSN.
Заключение
До начала написания этой статьи я отдавал себе отчёт, насколько это обширная тема, и как много времени займёт составление детального материала. Как оказалось, мои представления были слишком оптимистичными, и на написание ушло в два раза больше времени, чем я предполагал. Зато в процессе я узнал много нового.
Рекомендую к прочтению отличный и полный обзор по БД — Архитектура Базы Данных. Сто десять страниц хорошо составленной информации, как ни странно, написано языком, понятным даже новичку. Этот обзор в основном про архитектурные концепции, а не про алгоритмы и структуры данных; очень помог мне разработать структуру моей статьи.
Теперь вы точно знаете, как работает реляционная база данных! И, конечно, вам понятны следующие тезисы:
- индексы B+деревьев,
- общая структура БД,
- оптимизация с учётом затрат,
- операторы объединения,
- назначение буферного пула,
- управление транзакциями.
Но, поверьте, я рассказал далеко не про все хитрости БД. Не затронуты, например, следующие темы:
- управление кластеризованными БД и глобальными транзакциями,
- создание снэпшотов работающей БД,
- эффективное хранение и сжатие данные,
- управление памятью.
Вооружённые таким багажом знаний, подумайте лишний раз, выбирая между сырыми NoSQL базами данных и проверенными временем реляционными БД. Не поймите меня неверно: некоторые NoSQL базы очень даже ничего. Но это всё же новые технологии, решающие конкретные проблемы конкретных приложений.
В общем, надеюсь, если кто-то спросит вас: «Как работает реляционная БД?», вы теперь сможете дать достойный ответ. Или, в крайнем случае, - ссылку на эту статью.
Читайте так же статьи по теме: